期末考完吃飽太閒、精力過剩,做了一份關於北京清華的台港澳申請/錄取的數據分析
結果的確挺有意思的,在這邊跟大家分享
思路
數據取自清华大学研究生招生网,這個網站每年都會公布當年的申請/錄取名單(院系&編號),但是只會放在上面一陣子,在隔年開始招生前就把公告撤走,但可以透過網站時光機來獲取過去的申請/錄取名單公告,再透過sublime text的multiple cursor快速將其手動整理成csv,並且使用python進行視覺化分析
期末考完吃飽太閒、精力過剩,做了一份關於北京清華的台港澳申請/錄取的數據分析
結果的確挺有意思的,在這邊跟大家分享
數據取自清华大学研究生招生网,這個網站每年都會公布當年的申請/錄取名單(院系&編號),但是只會放在上面一陣子,在隔年開始招生前就把公告撤走,但可以透過網站時光機來獲取過去的申請/錄取名單公告,再透過sublime text的multiple cursor快速將其手動整理成csv,並且使用python進行視覺化分析

一直以來就嚷著要寫桌面程式,遲遲沒有動力研究
最近因為工作上需要寫一套跨平台的桌面小程式,終於用python的tkinter寫了一套簡單的GUI,但由於畫面過於簡陋,老闆在嫌棄之餘還用Java重新開發(驚)
深受打擊的我決定重新選用框架,直接挑功能最強、社群支援最廣的Qt來進行開發
開發環境:Mac OSX 10.12.3
語言版本:Python 3.5.0
其他版本:Qt Creator 4.2.1, Based on Qt 5.8

最近在爬學校老舊的網站,遇上了沒有指定charset的網頁,造成了不少困擾
將網頁wget下來後打開長這個樣子,一堆亂碼

於是,我決定用聽說很好用的chardet來找出網頁是採用何種encoding的
import requests import chardet url = "http://dormapply2.adm.nctu.edu.tw/SecondResult/Second105.html" r = requests.get(url) print(chardet.detect(r.content))
自動檢測結果如下
{'confidence': 0.99, 'encoding': 'GB2312'}
喔喔太好了!原來是GB2321,於是我便在BeautifulSoup這邊指定編碼
soup = BeautifulSoup(r.content, "lxml", from_encoding="gb2312") print(soup.title.text)
結果印出了個None, 後來上網一查才發現,微軟將gb2312 / gbk 映射為 gb18030
好吧,那我就再改一次
soup = BeautifulSoup(r.content, "lxml", from_encoding="gb18030") print(soup.title.text)
結果印出了奇怪的東西:
材顶琿だ祇挡狦
不對阿,業障很重誒
於是乎我決定到處走走,去抓抓看住宿服務組的其他網頁是用什麼編碼的
發現大部分的網頁是採用big5編碼的,
soup = BeautifulSoup(r.content, "lxml", from_encoding="big5") print(soup.title.text)
這次總算成功了!
第二階段分發結果
透過這次的經驗我學到
在設計爬蟲的時候,不能只靠Libarary來判斷編碼
透過同儕網頁的編碼形式來猜測該網頁的編碼,也是很不錯的方法
有興趣的人可以參考我的專案 dorm-crawler
#MachineLearning?

在將資料匯入資料庫之前,我們必須先做一些適當的處理
並且做一些適當的前處理,才能順利地將資料整合
可以用 tree 這個指令(需另外安裝, apt / brew 皆可安裝),觀察資料夾的結構長什麼樣子
tree -d .
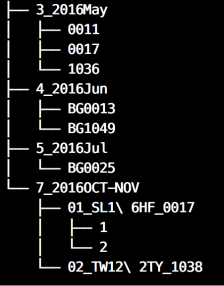
仔細觀察後,發現是一個樹狀結構
而在每個末端資料夾上都有滿滿的CSV,具備有以下特性
於是我決定先把所有末端資料夾內的CSV進行合併,再以資料夾路徑名稱來命名
新建一個資料夾叫data, 把原本的資料都丟進去, 再把合併完成的csv放到output資料夾內
先來看一下code
| import os | |
| import pandas as pd | |
| import time | |
| for root, dirs, files in os.walk("data"): | |
| if not dirs: | |
| df_list = [] | |
| start = time.time() | |
| print(root) | |
| for file in files: | |
| path = root+"/"+file | |
| if(os.path.getsize(path)) > 600000: | |
| df = pd.read_csv(path, encoding = "ISO-8859-1", header=3) | |
| df = df.dropna(how='all') | |
| df_list.append(df) | |
| if df_list: | |
| df_concat = pd.concat(df_list, ignore_index=True) | |
| df_concat.columns = [c.replace("\n"," ") for c in list(df_concat.columns)] | |
| filename = "_".join(root.split("/")[1:]) + ".csv" | |
| df_concat.to_csv("output/" + filename, index=False) | |
| print("[+] " + filename) | |
| print(round(time.time() – start, 2)) |
這份22行的code實現了以下幾點功能
Python實在是太方便了
