
在將資料匯入資料庫之前,我們必須先做一些適當的處理
並且做一些適當的前處理,才能順利地將資料整合
可以用 tree 這個指令(需另外安裝, apt / brew 皆可安裝),觀察資料夾的結構長什麼樣子
tree -d .
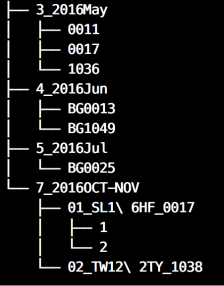
仔細觀察後,發現是一個樹狀結構
而在每個末端資料夾上都有滿滿的CSV,具備有以下特性
- 2000多個,每個2MB左右
- 檔案命名皆為流水號 ( e.g 0001.csv, 0002.csv, …)
- 檔案資料欄位格式皆相同
於是我決定先把所有末端資料夾內的CSV進行合併,再以資料夾路徑名稱來命名
新建一個資料夾叫data, 把原本的資料都丟進去, 再把合併完成的csv放到output資料夾內
先來看一下code
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| import os | |
| import pandas as pd | |
| import time | |
| for root, dirs, files in os.walk("data"): | |
| if not dirs: | |
| df_list = [] | |
| start = time.time() | |
| print(root) | |
| for file in files: | |
| path = root+"/"+file | |
| if(os.path.getsize(path)) > 600000: | |
| df = pd.read_csv(path, encoding = "ISO-8859-1", header=3) | |
| df = df.dropna(how='all') | |
| df_list.append(df) | |
| if df_list: | |
| df_concat = pd.concat(df_list, ignore_index=True) | |
| df_concat.columns = [c.replace("\n"," ") for c in list(df_concat.columns)] | |
| filename = "_".join(root.split("/")[1:]) + ".csv" | |
| df_concat.to_csv("output/" + filename, index=False) | |
| print("[+] " + filename) | |
| print(round(time.time() – start, 2)) |
這份22行的code實現了以下幾點功能
- 歷遍所有資料夾,當前root底下沒有其他資料夾(達到末端),讀取root內所有的檔案
- 確保每一個檔案都大於600kb
- 在這批資料中,有許多空白的CSV檔案大小約 5xx kb,沒有必要讀取
- 以ISO-8859-1編碼讀取(對方匯出資料時的編碼似乎是採用Latin-1)
- 指定CSV檔的第四行為資料欄位(並且捨棄前三行我們不需要的header)
- 將所有資料欄位皆為空的row刪除
- 把處理好的dataframe存入一個list內,繼續處理下一個檔案
- 確保每一個檔案都大於600kb
- 處理完所有檔案後,將list內的dataframe全部拼接起來,並且給予新的index
- 將資料欄位中的\n給拿掉(沒錯,居然有人 資料欄位使用換行符\n…)
- 將檔案路徑的"/"以"_"取代之,並且捨棄最前面的 “data"字串,最後再給予.csv副檔名
- 用pandas輸出CSV,儲存在output資料夾內
- 在這裡輸出時忽略index,因為他不重要
- 輸出在處理這份csv上,總共花了多少時間
Python實在是太方便了
